
 by
by Introduction
In 2025, data is growing at an exponential rate due to cloud applications, AI systems, IoT devices, mobile apps, and digital platforms. Every second, businesses generate massive volumes of structured, semi-structured, and unstructured data.
Traditional databases and data warehouses are no longer sufficient to handle this scale efficiently. They are rigid, expensive, and not designed for modern real-time analytics needs.
This is where Data Lake Architecture becomes a game-changer. It allows organizations to store all types of data in raw format, process it flexibly, and extract meaningful insights using AI, machine learning, and advanced analytics.
A well-designed data lake is not just a storage system—it is a complete big data processing ecosystem that supports scalability, performance, and innovation.
What is Data Lake Architecture?
A Data Lake Architecture is a modern data management framework that allows organizations to store massive amounts of raw data in a centralized repository.
Unlike traditional systems, it follows a schema-on-read approach, meaning data is structured only when it is analyzed, not when it is stored.
This makes data lakes extremely flexible for analytics, AI, and data science workloads.
A typical data lake includes:
- Data ingestion pipelines
- Scalable cloud storage
- Processing engines
- Metadata management
- Security and governance systems
- Analytics and visualization tools
Why Data Lakes Are Important
Modern enterprises need faster decision-making and real-time insights. Data lakes solve several major challenges:
- Handling massive data growth
- Supporting multiple data formats
- Reducing storage costs
- Enabling real-time analytics
- Supporting AI/ML applications
Because of these advantages, companies are rapidly shifting from traditional data warehouses to data lake or lakehouse architectures.
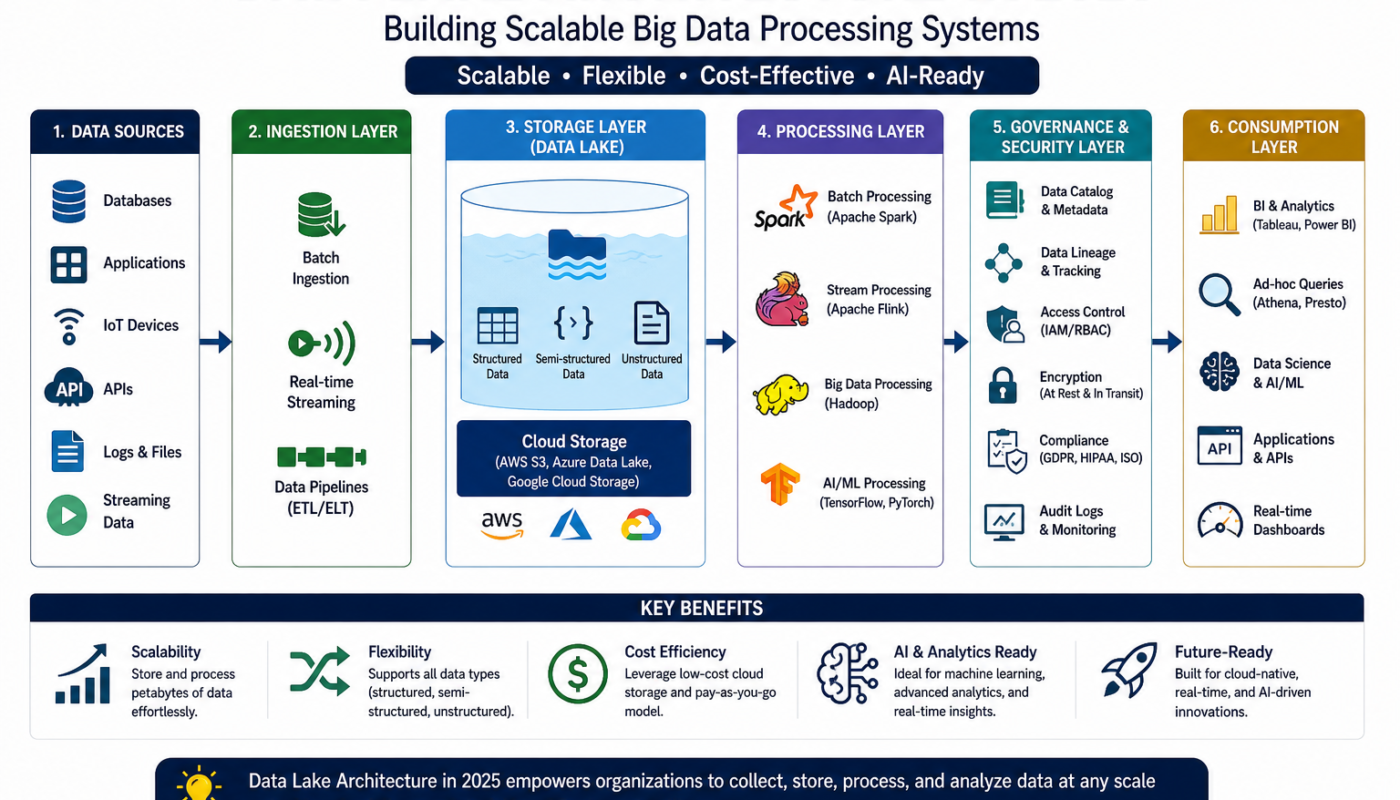
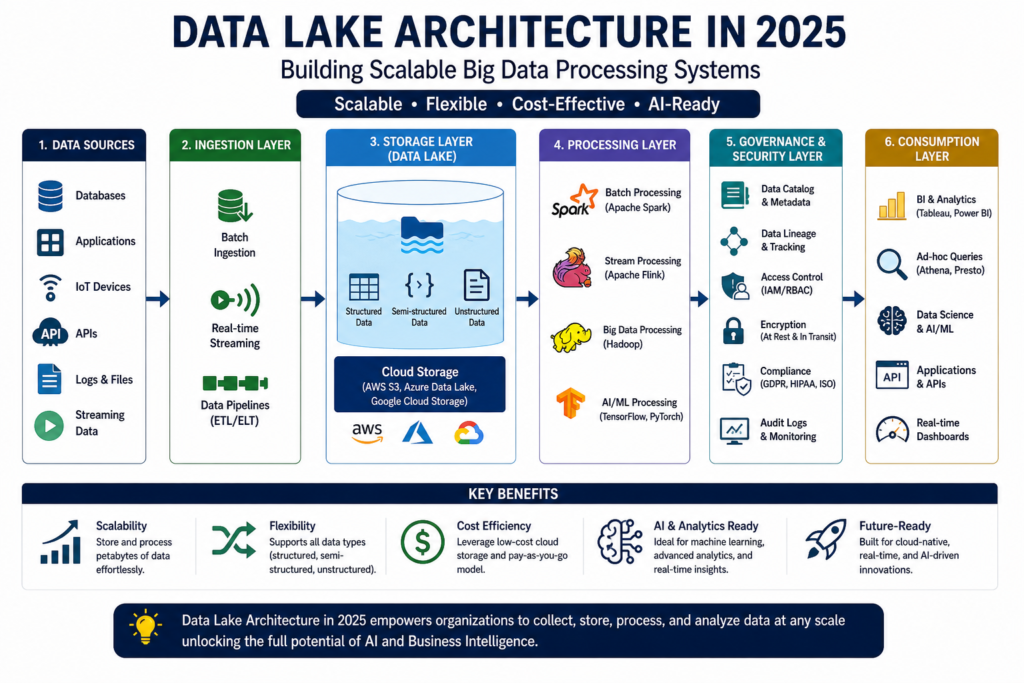
Core Layers of Data Lake Architecture
1. Data Ingestion Layer
This is the entry point of the data lake.
It collects data from multiple sources such as:
- Databases (SQL/NoSQL)
- APIs
- IoT devices
- Mobile applications
- Cloud applications
- Streaming platforms
Modern ingestion systems use real-time streaming (Kafka, Kinesis) and batch pipelines to ensure continuous data flow.
2. Storage Layer
The storage layer is the heart of the data lake.
Key features:
- Stores raw data in original format
- Highly scalable cloud storage
- Cost-efficient architecture
Popular cloud storage systems:
This layer allows organizations to store petabytes or even exabytes of data without structural limitations.
3. Processing Layer (Compute Layer)
This layer transforms raw data into meaningful insights.
Processing in a data lake relies on advanced big data technologies like Spark and Hadoop for real-time and batch analytics.
Common technologies:
- Apache Spark
- Apache Hadoop
- Apache Flink
- Databricks
- AI/ML frameworks (TensorFlow, PyTorch)
It supports:
- Batch processing
- Real-time analytics
- Machine learning pipelines
4. Metadata and Data Catalog Layer
Without metadata, a data lake becomes a “data swamp.”
This layer provides:
- Data indexing
- Search capabilities
- Data lineage tracking
- Data classification
Tools like AWS Glue Data Catalog and Apache Atlas help manage metadata efficiently.
5. Security and Governance Layer
Security is a top priority in modern data lake systems.
This layer ensures:
- Data encryption (at rest & in transit)
- Role-based access control (RBAC)
- Compliance (GDPR, HIPAA, ISO)
- Audit logs and monitoring
It ensures that sensitive business data remains protected at all times.
6. Analytics and Consumption Layer
This is where users interact with data.
Tools used:
- Tableau
- Power BI
- Looker
- SQL engines (Presto, Athena)
This layer enables:
- Business intelligence
- AI/ML model training
- Real-time dashboards
Data Lake Architecture Flow
A simple flow looks like this:
Data Sources → Ingestion → Storage → Processing → Governance → Analytics Tools
This flow ensures smooth movement of data from raw input to actionable insights.
Key Benefits of Data Lake Architecture
1. Scalability
Handles massive data growth without performance issues.
2. Flexibility
Supports all types of data formats.
3. Cost Efficiency
Uses low-cost cloud storage instead of expensive traditional systems.
4. AI & ML Ready
Perfect for training machine learning models on large datasets and enabling artificial intelligence applications.
5. Real-Time Insights
Supports streaming analytics for instant decision-making.
Data Lake Architecture Explained
Learn how modern big data systems work and how enterprises design scalable data lake architectures.
Modern Trends Data Lake Architecture
1. Lakehouse Architecture
Combines the benefits of data lakes and data warehouses into a unified system.
2. Real-Time Data Processing
Uses streaming tools like Kafka and Flink for instant analytics.
3. AI-Driven Data Management
Automates data classification, anomaly detection, and optimization.
4. Cloud-Native Systems
Fully managed services replacing traditional Hadoop clusters.
5. Serverless Data Lakes
No infrastructure management required—pay only for usage.
Use Cases of Data Lake Architecture
- Cybersecurity threat detection
- Fraud detection in banking systems
- Customer behavior analysis
- IoT analytics in smart devices
- AI-based recommendation systems
- Healthcare data processing
Best Practices for Building a Scalable Data Lake
- Use cloud-native storage solutions
- Implement strong data governance policies
- Maintain proper metadata catalogs
- Separate compute and storage layers
- Automate data pipelines using AI/ML tools
- Monitor performance continuously
Conclusion
Data Lake Architecture in 2025 is the foundation of modern data-driven enterprises. It enables organizations to store massive datasets, process them efficiently, and extract insights using AI and analytics.
With the rise of cloud computing, real-time streaming, and AI-powered automation, data lakes are evolving into intelligent systems that power digital transformation across industries.
Businesses that adopt scalable data lake architectures today will lead the future of big data innovation.


